Trouver des doublons sur une ou plusieurs colonnes avec SQL Server est une tâche cruciale pour maintenir l’intégrité et la précision de vos bases de données.
Les doublons peuvent fausser vos analyses, conduisant à des décisions commerciales potentiellement coûteuses. Ce guide propose une approche étape par étape pour trouver des enregistrements en double dans SQL Server en utilisant des requêtes T-SQL, adaptées à divers scénarios que vous pourriez rencontrer.
Le problème : Des données en double dans une table SQL Server
Les enregistrements en double peuvent provenir de multiples sources, y compris des erreurs humaines lors de la saisie des données, l’absence de contraintes uniques dans la conception de la base de données, ou à la suite de processus de migration et d’intégration des données. De tels doublons peuvent compromettre la qualité des données et conduire à des résultats d’analyse incorrects.
La solution : Des requêtes T-SQL pour trouver les doublons
Le langage Transact-SQL (T-SQL) de SQL Server offre des solutions robustes mais simples pour identifier les enregistrements en double. Nous explorerons différentes méthodes pour localiser et afficher les doublons, vous permettant de maintenir une base de données propre et fiable.
Avant de plonger dans les spécificités, créons une table d’exemple pour illustrer comment les doublons peuvent être identifiés dans SQL Server.
Préparation de Notre Table d’Exemple avec des Doublons
Considérons que nous avons une table de registres de ventes nommée SalesRecords avec la structure suivante :
/* Code fourni par https://expert-only.com */
CREATE TABLE SalesRecords (
SalesRecordID INT IDENTITY(1,1) PRIMARY KEY,
ProductID INT,
SaleDate DATE,
Quantity INT
);
Pour ajouter des données d’exemple (y compris des doublons) dans la table SalesRecords, utilisez :
/* Code fourni par https://expert-only.com */ INSERT INTO SalesRecords (ProductID, SaleDate, Quantity) VALUES (1, '2022-01-01', 10), (2, '2022-01-02', 15), (1, '2022-01-01', 10), -- Doublon (3, '2022-01-03', 20), (2, '2022-01-02', 15); -- Doublon
Passons maintenant à l’identification de ces enregistrements en double.
Table of Contents
Trouver des Doublons sur une Seule Colonne
Pour trouver des doublons dans une seule colonne de la table SalesRecords, telle que ProductID, vous pouvez utiliser la requête suivante :
/* Code fourni par https://expert-only.com */ SELECT ProductID, COUNT(*) AS NumerOfLines FROM SalesRecords GROUP BY ProductID HAVING COUNT(*) > 1;
Cette requête liste les produits vendus à plusieurs reprises, indiquant des doublons potentiels basés sur le ProductID.
Afficher les Doublons sur Plusieurs Colonnes
Si les doublons sont définis par une combinaison de colonnes, disons ProductID et SaleDate, la requête s’ajuste pour grouper par ces colonnes :
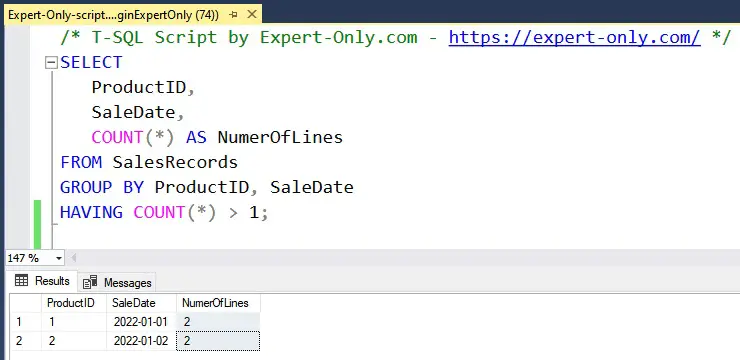
/* Script T-SQL par Expert-Only.com - https://expert-only.com/ */ SELECT ProductID, SaleDate, COUNT(*) AS NumerOfLines FROM SalesRecords GROUP BY ProductID, SaleDate HAVING COUNT(*) > 1;
Ce script T-SQL identifie les enregistrements où le même produit a été vendu à la même date, mettant en évidence les doublons basés à la fois sur le ProductID et le SaleDate.
Techniques plus avancées de gestion des doublons
Au-delà des bases, gérer les doublons dans SQL Server peut impliquer des scénarios plus sophistiqués nécessitant des techniques T-SQL avancées. Explorons quelques situations communes mais plus complexes que vous pourriez rencontrer dans vos efforts de gestion de base de données.
Supprimer les doublons et conserver une seule ligne
Dans certains cas, vous pourriez vouloir non seulement identifier les doublons mais aussi les supprimer tout en conservant une instance de l’enregistrement dupliqué. Cela peut être réalisé en utilisant la fonction ROW_NUMBER(), qui attribue un numéro unique à chaque ligne dans l’ordre que vous spécifiez. Ainsi, vous pouvez conserver la première occurrence et supprimer les suivantes.
/* Code T-SQL par https://expert-only.com/ */
WITH CTE_Duplicates AS (
SELECT *,
ROW_NUMBER() OVER(PARTITION BY ProductID, SaleDate ORDER BY SalesRecordID) AS RowNumber
FROM SalesRecords
)
DELETE FROM CTE_Duplicates WHERE RowNumber > 1;
Cette requête utilise une Expression de Table Commune (CTE) pour partitionner les données par ProductID et SaleDate, ordonne les doublons par SalesRecordID, et supprime toutes les instances sauf la première de chaque ensemble de doublons.
Touver les doublons sur plusieurs tables SQL Server
Parfois, les doublons ne se limitent pas à une seule table mais sont répartis sur plusieurs tables. Identifier ceux-ci nécessite une opération JOIN pour rassembler les données pertinentes avant d’appliquer la logique de détection de doublons.
/* T-SQL code by https://expert-only.com/ */
SELECT
a.ProductID,
a.SaleDate
FROM SalesRecords a
JOIN AnotherTable b
ON a.ProductID = b.ProductID
AND a.SaleDate = b.SaleDate
GROUP BY
a.ProductID,
a.SaleDate
HAVING COUNT(*) > 1;
Trouver des doublons sur de grands volumes avec les fonctions de hachage
Pour de très grands ensembles de données, la performance peut devenir un problème lors de l’identification des doublons. Une manière d’améliorer l’efficacité est d’utiliser des fonctions de hachage pour réduire la quantité de données devant être comparées.
La fonction HASHBYTES de SQL Server peut être utilisée pour créer un hachage du contenu de chaque ligne, qui peut ensuite être comparé au lieu des données complètes de la ligne.
/* T-SQL code by https://expert-only.com/ */
SELECT
HashValue,
COUNT(*) AS NumerOfLines
FROM (
SELECT HASHBYTES('SHA1', CONCAT(ProductID, SaleDate, Quantity)) AS HashValue
FROM SalesRecords
) AS HashedTable
GROUP BY HashValue
HAVING COUNT(*) > 1;
A propos des doublons dans les tables SQL Server
Nous venons d’apprendre à trouver des doublons dans une table donnée avec SQL Server afin de maintenir l’intégrité des données dans les bases. En utilisant des requêtes T-SQL, vous pouvez identifier et gérer efficacement les données en double, assurant que vos analyses restent précises et fiables.
Que vous traitiez des doublons sur une seule colonne ou des scénarios plus complexes impliquant plusieurs champs, SQL Server fournit les outils dont vous avez besoin pour garder vos données propres.


Soyez le premier à commenter