Find duplicate records on one or multiple columns in SQL Server is a crucial task for maintaining data integrity and accuracy in your databases.
Duplicates can skew your analysis, leading to potentially costly business decisions. This guide provides a step-by-step approach to finding duplicate records in SQL Server using T-SQL queries, catering to various scenarios you might encounter.
Table of Contents
Problem: Duplicate Data in Your Database
Duplicate records can arise from multiple sources, including human error during data entry, lack of unique constraints in database design, or as a result of data migration and integration processes. Such duplicates can compromise data quality and lead to incorrect analysis results.
Solution: Use T-SQL Queries to Identify Duplicates
SQL Server’s Transact-SQL language (T-SQL) offers robust but simple solutions to identify duplicate records. We will explore different methods to locate and display the duplicates, ensuring you can maintain a clean and reliable database.
Before diving into the specifics, let’s create a sample table to illustrate how duplicates can be identified in SQL Server.
Preparing Our Sample Table with Duplicates
Consider we have a sales records table named SalesRecords with the following structure:
/* Code provided by https://expert-only.com */
CREATE TABLE SalesRecords (
SalesRecordID INT IDENTITY(1,1) PRIMARY KEY,
ProductID INT,
SaleDate DATE,
Quantity INT
);
To add some sample data (including duplicates) into the SalesRecords table, use:
/* Code provided by https://expert-only.com */ INSERT INTO SalesRecords (ProductID, SaleDate, Quantity) VALUES (1, '2022-01-01', 10), (2, '2022-01-02', 15), (1, '2022-01-01', 10), -- Duplicate (3, '2022-01-03', 20), (2, '2022-01-02', 15); -- Duplicate
Now, let’s move on to identifying these duplicate records.
Use Case 1: Find Duplicate Records Based on a Single Column
To find duplicates in a single column of the SalesRecords table, such as ProductID, you can use the following query:
/* Code provided by https://expert-only.com */ SELECT ProductID, COUNT(*) AS NumerOfLines FROM SalesRecords GROUP BY ProductID HAVING COUNT(*) > 1;
This query lists products sold on multiple occasions, indicating potential duplicates based on the ProductID.
Use Case 2: Find Duplicate Records Based on Multiple Columns
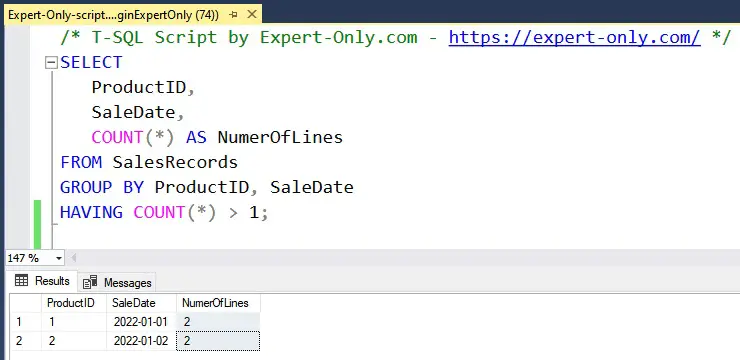
If duplicates are defined by a combination of columns, say ProductID and SaleDate, the query adjusts to group by these columns:
/* T-SQL Script by Expert-Only.com - https://expert-only.com/ */ SELECT ProductID, SaleDate, COUNT(*) AS NumerOfLines FROM SalesRecords GROUP BY ProductID, SaleDate HAVING COUNT(*) > 1;
This T-SQL script identifies records where the same product was sold on the same date, highlighting duplicates based on both the ProductID and SaleDate.
About More Advanced Deduplication Techniques
Beyond the basics, managing duplicates in SQL Server can involve more sophisticated scenarios requiring advanced T-SQL techniques. Let’s explore a few common but more complex situations you might encounter in your database management efforts.
Removing Duplicates While Retaining One Unique Record
In some cases, you might not just want to identify duplicates but also remove them while keeping one instance of the duplicated record. This can be achieved using the ROW_NUMBER() function, which assigns a unique number to each row in the order you specify. By doing so, you can keep the first occurrence and delete the subsequent ones.
/* T-SQL code by https://expert-only.com/ */
WITH CTE_Duplicates AS (
SELECT *,
ROW_NUMBER() OVER(PARTITION BY ProductID, SaleDate ORDER BY SalesRecordID) AS RowNumber
FROM SalesRecords
)
DELETE FROM CTE_Duplicates WHERE RowNumber > 1;
This query uses a Common Table Expression (CTE) to partition the data by ProductID and SaleDate, orders the duplicates by SalesRecordID, and deletes all but the first instance of each duplicate set.
Identifying Duplicates Across Multiple Tables
Sometimes, duplicates are not confined to a single table but spread across multiple tables. Identifying these requires a JOIN operation to bring the relevant data together before applying duplicate detection logic.
/* T-SQL code by https://expert-only.com/ */
SELECT
a.ProductID,
a.SaleDate
FROM SalesRecords a
JOIN AnotherTable b
ON a.ProductID = b.ProductID
AND a.SaleDate = b.SaleDate
GROUP BY
a.ProductID,
a.SaleDate
HAVING COUNT(*) > 1;
This example shows how to identify duplicates between SalesRecords and AnotherTable based on ProductID and SaleDate, which can be particularly useful when consolidating data from different sources.
Find Duplicate Records in Large Data Sets using Hash Functions
For very large data sets, performance can become an issue when identifying duplicates. One way to improve efficiency is by using hash functions to reduce the amount of data that needs to be compared. SQL Server’s HASHBYTES function can be used to create a hash of each row’s content, which can then be compared instead of the full row data.
/* T-SQL code by https://expert-only.com/ */
SELECT
HashValue,
COUNT(*) AS NumerOfLines
FROM (
SELECT HASHBYTES('SHA1', CONCAT(ProductID, SaleDate, Quantity)) AS HashValue
FROM SalesRecords
) AS HashedTable
GROUP BY HashValue
HAVING COUNT(*) > 1;
This approach computes a SHA1 hash of the concatenation of the ProductID, SaleDate, and Quantity for each record. By comparing these hashes, you can quickly identify duplicates, significantly improving the performance on large datasets.
These advanced techniques extend the basic principles of duplicate detection in SQL Server, offering powerful tools for maintaining data quality in more complex scenarios.
Final Thoughts on Detecting Duplicate Records
We just learnt to find duplicate records in a given table in order to maintain the data integrity inside SQL Server databases. By leveraging T-SQL queries, you can effectively identify and handle duplicate data, ensuring your analyses remain accurate and reliable.
Whether dealing with single-column duplicates or more complex scenarios involving multiple fields, SQL Server provides the tools you need to keep your data clean.


Be the first to comment